✅ What is the difference between random I/O and sequential I/O?
✅ What is an index in a database?
data structure to help speed up data retrieval operation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| - Employee table
| EmpID | Name | Department |
| ----- | ------- | ---------- |
| 101 | Alice | HR |
| 102 | Bob | Sales |
| 103 | Charlie | HR |
- create Index on EmpID
Key | Value (RowID / Pointer)
------+------------------------
101 | → Row 1
102 | → Row 2
103 | → Row 3
- SQL
SELECT * FROM Employees WHERE EmpID = 102;
|
- index is always SORTED
- 👍🏻
SELECT, scan entire table ❌, quickly locate data ⭕️ - 👎🏻
INSERT, UPDATE, DELETE
✅ How does an index work?
✅ What factors should you consider when creating an index?
- 1️⃣ Query patterns: add index to
WHERE, JOIN, ORDER BY, GROUP BY - 2️⃣ Selectivity: high selectivity = many unique values
- 3️⃣ Read vs. Write workload: index speed up reads, slow down writes
- 4️⃣ Table size: index is better for large tables
- 5️⃣ Sort, Group: index help sort, grouping columns
- 6️⃣ uniqueness: use
UNIQUE index to enforce data integrity
1
2
3
4
5
| When is index most efficient?
- 👍🏻 GROUP BY, ORDER BY
- 👍🏻 high cardinality, lots of unique values
- 👍🏻 more read, not write
- 👍🏻 big table
|
✅ What factors should we be aware when creating index?
- 1️⃣ aware of Range conditions like
BETWEEN, LIKE, <, > - index is only used up to the column where range starts
- columns after that in multi-column index are ignored
-- composite index in month, city
WHERE month BEWTEEN 202301 AND 202312
AND city = Seoul
-- month use index
-- city might NOT use index
- 2️⃣ Use Equality Conditions
- use
= and IN
-- replace range with equality
-- not efficient
AND month BETWEEN 200801 AND 200812
-- more efficient
AND month IN ('200801','200802','200803','200804','200805','200806','200807','200808','200809','200810','200811','200812')
-- column is String
WHERE CAST(col AS INT) = 123
-- 👎🏻 disable index due to data mismatch
✅ What should you be careful about when using indexes?
- ⚠️ overuse of index slow down write operations
- ⚠️ index maintenance overhead: changing indexed columns often lead to constant re-balancing of index structure
- ⚠️ using index in low cardinality columns: if use index in
gender column with only a few distinct values, index will not be effective! - ⚠️ correct order in
composite(multi-level) index: composite index query should start with first column. Put high-cardinality columns first
✅ Is it good to create many indexes on a table?
💡 What is a covering index?
covering index: index that contains all the columns needed to satisfy a query
DB can answer the query just using index, WO accessing table
- index holds required data
- DB DOES NOT NEED to access actual table rows
- no table lookup
- 👍🏻 reduce I/O, just get data from index, not real table
- 👍🏻 faster read, do not have to access table
- 👍🏻 efficient for read
1
2
3
4
5
6
7
8
9
10
11
12
13
| CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(255),
age INT
);
-- create covering index
CREATE INDEX idx_email_age ON users (email, age);
SELECT age FROM users WHERE email = 'john@example.com';
-- WHERE clause knows wmail
-- SELECT needs only age
-- index idx_email_age already has both email and age
|
💡 What is a multi-column index (or composite index)?
multi-column index: single index that includes multiple columns from table
useful when queries filter or sort using more than one column
- when queries involve more than one column
- ⭐️ order of column matters
- index is most effective when query filters based on leftmost columns first
- better to set from broad to narrow categories
- 대분류 ➡️ 중분류 ➡️ 소분류
food ➡️ vegetable ➡️ carrot
1
| an index on (first_name, last_name) can efficiently support queries filtering on first_name or both, but not just last_name
|
- example of composite index
1
2
3
4
5
6
7
8
9
10
| CREATE INDEX idx_email_age ON users (email, age);
-- ⭕️ efficient, use leftmost column
SELECT * FROM users WHERE email = 'john@example.com';
-- ⭕️ efficient, use both index columns
SELECT * FROM users WHERE email = 'john@example.com' AND age = 30;
-- ❌ not efficient, skips first column
SELECT * FROM users WHERE age = 30;
|
💡 What are nodes in B-Tree and B+Tree indexes?
- root node: topmost node, one node per tree, search starts here
- internal node: node that routes search paths, between root and leaf node
- leaf node: most bottom node, node that stores actual data(same leaf node, same depth)
- linked leaf nodes:
B+Tree only, connected from left ➡️ right for range scanning
1
2
3
4
5
| [50] ← Root
/ \
[20, 40] [60, 80] ← Internal nodes
|
[10] [20] [30] [40] ← Leaf nodes
|
💡 Can you explain the difference between B-Tree and B+Tree indexes?
- 공통점: balanced tree structures used in indexing
차이점: how/where they store data
- ✔️ B-Tree: store key and pointer in both internal and leaf nodes
- tree with sorted keys
DB navigates through the tree to find target key, get value, then access the associated data
- 👍🏻 fast point lookup
- 👎🏻 increase node size and I/O
- 👎🏻 need more memory, data is saved both in root, branch, leaf node
1
2
3
4
5
6
| internal node: store key ➕ pointer
leaf node: store key ➕ pointer
leaf connection: not linked
point lookup: fast
range query: slow(internal nodes are not linked, has to go through multiple levels)
use: old DBs
|
1
2
3
4
5
6
7
| if DB is [5, 10, 15, 20, 25, 30, 35, 40]
[15] /*internal node*/
/ \
[5,10] [20,25,30] /*leaf nodes*/
\
[35,40]
|
- ✔️ B+Tree: store
key and pointer in only in leaf node - store only
key in root, internal node pointer to actual data resides in leaf nodes- leaf nodes are linked by
LinkedList together - 👍🏻 fast range query, support sequential scans
BETWEEN, <, >, LIKE %abc% - 👍🏻 memory efficiency, only has to save data in leaf node
- used as default in modern databases
- used in
MySQL, PostgreSQL
1
2
3
4
5
6
| internal node: only keys
leaf node: store key ➕ pointer
leaf connection: linked
point lookup: fast
range query:fast(leaces are linked)
use: modern RDBMS
|
1
2
3
4
5
6
7
8
9
10
11
| if DB is [5, 10, 15, 20, 25, 30, 35, 40]
[15] /*internal node: store only keys*/
/ \
[5,10] [20,25] /*leaf node: store key and data*/
\
[30,35]
\
[40]
Leaf node chain: [5,10] → [20,25] → [30,35] → [40] /*linked*/
|
- example of real-world query
1
2
3
4
5
6
| CREATE INDEX idx_age ON users (age);
SELECT id, email
FROM users
WHERE age BETWEEN 20 AND 30
ORDER BY id;
|
💡 What is a Hash index, and when would you use it?
use hash function to map search keys into fixed-sized bucket number
💡 What is a clustering index?
determine physical order of data in the table
- rows are stored on disk in the same order as index
- only ONE clustering index per table is possible
- Why? only one row can be
clustering index - (id순으로 정렬해둘지, 나이순으로 정렬해둘지, 날짜 순으로 정렬해 둘지 하나만 고를 수 있으니까)
- in InnoDB,
primary key is clustering index by default
1
2
3
4
5
6
7
8
9
10
11
12
13
| clustering index: created_at
+-----------------------------+
| posts Table (Physical Rows)|
+-----------------------------+
| id=9 | created_at=2023-01-01 |
| id=4 | created_at=2023-01-02 |
| id=12 | created_at=2023-01-03 |
| id=5 | created_at=2023-01-04 |
| id=7 | created_at=2023-01-05 |
+-----------------------------+
↑
(physically sorted)
|
- 👍🏻
RANGE queries like ORDER BY - 👍🏻 ordered scans are fast
- 👎🏻 if many
INSERT, DELETE, UPDATE, lot of re-ordering has to take place
1
2
| SELECT * FROM posts
WHERE created_at BETWEEN '2023-01-02' AND '2023-01-04';
|
- leaf node of the clustering index store the actual data rows and pointers
✅ What is a non-clustering index?
- index that DOES NOT affect the physical order of data in the table
- instead, use
index columns - and
pointer: point to where to find data in actual table row - thus, only store
index and pointer
1
2
3
4
5
| email → row location
------------------------------
alice@example.com → row ID 1
bob@example.com → row ID 2
carol@example.com → row ID 3
|
1
2
3
4
5
| SELECT * FROM users WHERE email = 'bob@example.com';
-- find email
-- then go to row ID 2 with pointer
-- then get user data
|
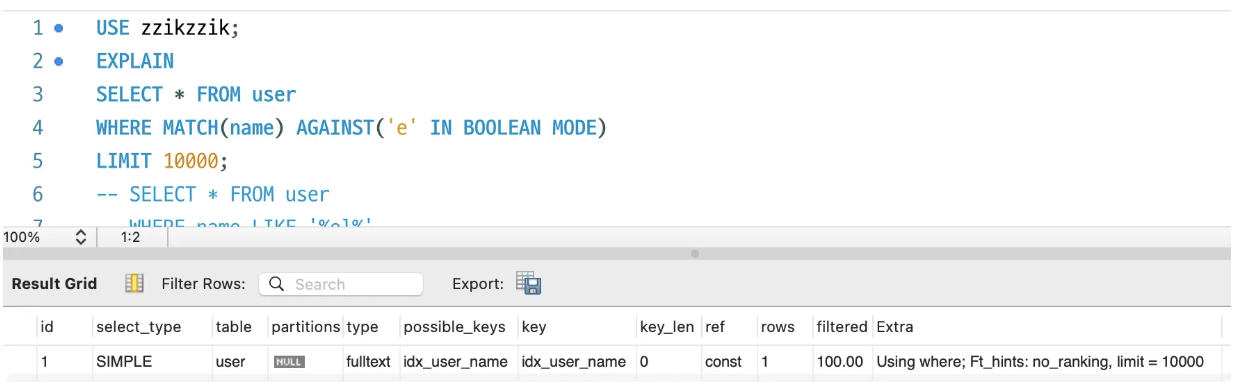
✅ What is a full-text index?
- specialized index used for searching large text data
- such as paragraph, documents hash- support advanced text search
- search
words inside text - 👍🏻
MATCH AGAINST
1
2
| SELECT * FROM posts
WHERE MATCH(content) AGAINST('database indexing');
|
- this query will return posts that mention
database or indexing - then, sort by relevance

✅ Can you explain different types of index scans in a database?
1
| SELECT name FROM users;
|
- ✔️ Index Range Scan: scan specific range based on conditions
BETWEEN, <, >, LIKE 'A%
1
| SELECT * FROM employees WHERE age BETWEEN 30 AND 40;
|
- ✔️ Index Unique Scan: retrieve single row with unique index
1
| SELECT * FROM users WHERE id = 123;
|
- ✔️ Index Skip Scan: when you are using composite index(multi-column index) but your query skips the first column
1
2
3
4
5
6
7
8
9
10
| -- have composite index on department, job_title
CREATE INDEX idx_dept_job ON employees(department, job_title);
-- however, run query on job_title
-- the query DOES NOT filter the first column
SELECT * FROM employees WHERE job_title = 'Manager';
-- in composite index, need to use first or both index in query
-- thus, normally, index will not be used
-- 🟢 with index skip scan, DB will use index smartly
|
1
2
| SELECT * FROM employees
WHERE department = 'Sales' AND job_title = 'Manager';
|
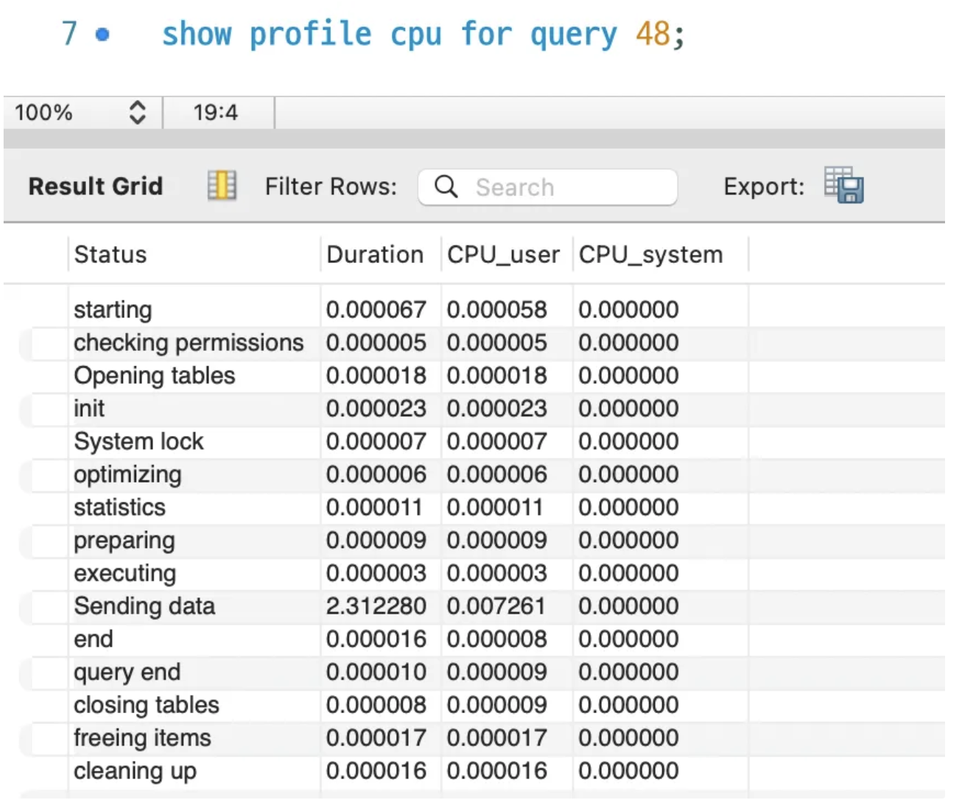
✅ Have you ever checked a query execution plan? Can you explain what it is and how you analyze it?
✅ What is a hint in SQL, and when would you use it?
1
2
3
| SELECT /*+ INDEX(employees idx_department) */ *
FROM employees
WHERE department = 'Engineering';
|
- ⚠️ overusing hints can reduce maintainability
✅ How do you check if an index is being used by a query?
✅ How does GROUP BY affect index usage in queries?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| -- Index: (country, gender, name)
-- ⭕️ index is used
SELECT country, COUNT(*)
FROM users
GROUP BY country;
SELECT country, gender, COUNT(*)
FROM users
GROUP BY country, gender;
-- ❌ index is NOT used
-- order is wrong
SELECT gender, country
FROM users
GROUP BY gender, country;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| 예) 인덱스 (a, b, c)가 있을 때
1. 인덱스가 적용되는 경우:
- GROUP BY a : 인덱스 첫 번째 컬럼인 a만 사용하므로, 인덱스 적용
- GROUP BY a, b : a와 b는 인덱스의 첫 번째와 두 번째 컬럼에 해당하므로, 인덱스 적용
- GROUP BY a, b, c : 모든 컬럼이 인덱스에 포함되어 있어 인덱스 적용
2. 인덱스가 적용되지 않는 경우:
- GROUP BY b : b는 두 번째 컬럼이지만 첫 번째 컬럼인 a가 포함되지 않아서, 인덱스가 적용되지 않음
- GROUP BY b, a : b가 첫 번째로 나오고, a는 두 번째로 나오기 때문에, 순서가 맞지 않아 인덱스가 적용되지 않음
- GROUP BY a, c, b, d : 인덱스에 포함되지 않은 d 컬럼이 있기 때문에, 인덱스가 적용되지 않음
|
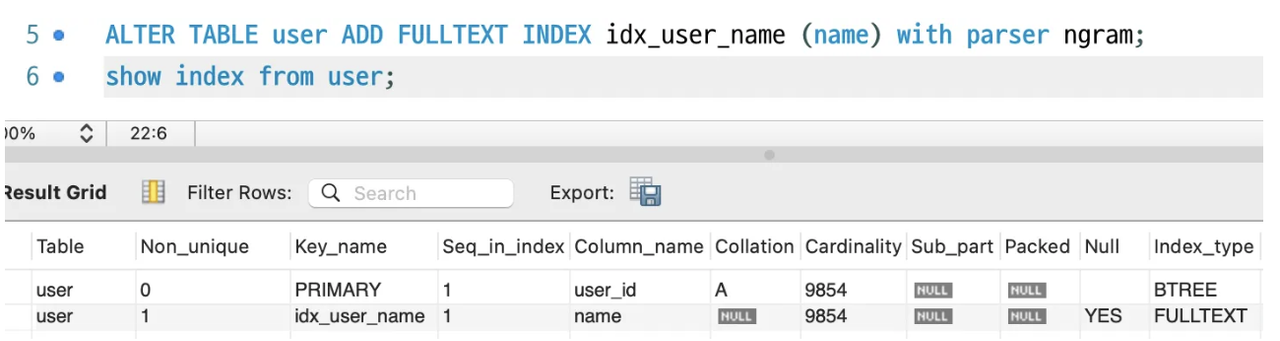
✅ How would you create an index on a table with name, country, and gender?
1
| CREATE INDEX idx_name_country_gender ON users(name, country, gender);
|
- ⚠️ Be careful, in
composite index including leading column is important!
- always include leading column
1
2
3
4
5
6
7
8
| -- ⭕️ use index
SELECT * FROM users WHERE name = 'John';
SELECT * FROM users WHERE name = 'John' AND country = 'Korea';
-- ❌ index will not be used
-- unless Index Skip Scan is enabled
SELECT * FROM users WHERE country = 'Korea';
|
- ⚠️ In
GROUP-BY, leading column and order is very important
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| -- ⭕️ use index
SELECT name, COUNT(*) FROM users
GROUP BY name;
SELECT name, country, COUNT(*) FROM users
GROUP BY name, country;
SELECT name, country, gender, COUNT(*) FROM users
GROUP BY name, country, gender;
-- ❌ index will not be used
-- leading column is not included
SELECT country, COUNT(*) FROM users
GROUP BY country;
-- ❌ index will not be used
-- order is wrong
SELECT country, name FROM users
GROUP BY country, name;
|